I initially worked through the first half of the fastai course with my wonderful colleagues at work a year ago or so (sometime during the pandemic beginning, time is non-linear in my mind now). Whilst it was instructive and I learnt a lot discussing and teaching to each other what we learned each week, I made the cardinal mistake of spending far too much time reading and watching rather than doing and trying. It has left me with a more surface understanding of the concepts than I’d like and a lacking practical ability for me to exercise what I know. I am determined to do it differently this time and work very hard to go through this course differently than how I would usually MOOC myself to death.
The main motivation for working through the fastai course is pure enjoyment and love for deep learning and machine learning, I honestly think its the magic of the future and its also re-ignited my love for math which was beaten out of my by demonic high school teachers. Secondly I’d like to professionally move to a role more dedicated to machine learning (deep learning if I can) and putting those models into production to drive excellent products. I love my current role and I owe my mentors I’ve gotten to know over the last ~5 years for my love of software engineering (and the belief that it’s a high craft to hone over a lifetime), my data obsession, my desire (and practice) to continually learn, and my deep enjoyment of collaborating to build great products and services. However I’ve spent many years deep in the bowels of a very large organisation (for Australia, we are a tiny nation full of spiders, not people) building platforms and tools for others to build products with and I think I’m finally at a cross-roads where I need to find a new challenge and domain to apply the skills I’ve got as well as learn from & teach new wonderful people I’m yet to collaborate with. I’m keen to be closer to customers and get a better feedback signal on what I’m building rather than constructing purely internal tooling that only makes sense or is useful in the context of the extremely bespoke organisation it powers.
Goals & Plan of Attack
Goal
Plan of Attack
Enjoy the time & Be Happy
Make sure to do problems and work that I’m excited about, difficult to track but something I want to not forget and make sure to reflect and focus on, hence why I’m declaring it as the first goal here!
Drastically Reduce Procrastination
Use Pomodoro style apps (Focus Keeper) to use time effectively & Do at least 25 minutes of study/work everyday
Build a Portofolio of Work
Contribute regularly to the Fastai Discord/Forums/Study Group (fastbunnies come join us on discord), Use Active Kaggle Competitions as data and problems to apply lessons to and blog my work here
Thankyou
I’d also like to shoutout to a few names that have both inspired me to begin and engage on a journey like this as well as even making a journey like this possible
Jeremy Howard | fastai
As the creator of the software package, one of the authors of the fastai book (Sylvain much love to you as well!), an incredible teacher of many topics (in particular the lessons on startups & APL), the chief motivator of prospective students to just get engaged and learn and post about what you’re doing as well as write what you learn (hopefully I’m taking on what you’re preaching by writing here?). None of what I’m doing and learning is feasibly as easy or possible without your work, thankyou.
Rachel Thomas | fastai
Without your class on data ethics and exposing me to this entire problem space, I don’t know what would have dropped the penny for me. You inspired and showed me awesome thinkers like Timnit Gebru, and got me interested in books like Weapons of Math Destruction by Cathy O’Neil. Thinking about data ethics and your talks have completely changed the way I view data I work with at work and personally in my life, I think I will forever be a better data practictioner and conscious of what I’m doing as well as what others are doing with data because of your work. You’ve also connected real problems I see in the world with the data that observes these problems and the models and data that cause these problems to the ethical and emotional experience of being a human. The welding of ethical philosophy and data work is a really powerful connection in my heart and mind that I’m thankful you showed me, your talks were truly mind blowing and expanding! I’m also really excited to take your fastai linear algebra course once I’ve completed the fastai lectures and written them here, thankyou.
Zach Meuller | fastai & huggingface
Without your hand-holding, I wouldn’t either be confident enough or hurdle the leap it is to contribute to open source. Your help and guidance with my first fastai contribution and PR solidified how great the fastai community was and you actively participated in an important learning moment for me. I’d also not feel like its possible to go from fastai to an incredible role like working at huggingface, all the while being a whole bunch younger than I am! I’m excited to take your walkwithfasti course after I’ve completed Rachel’s course and written about it here as well. You’re an inspiration, thankyou.
Radek Osmulski | NVIDIA & fastai
Radek, your journey similar to Zach’s from fastai to NVIDIA is equally inspiring and your book Meta Learning feels like a blueprint for the lessons and behaviours I need to work on. I strongly connected to the chapters and personal writing you expressed, your kaggle notebooks are also awesome and I’ve already learnt so much from you despite not consuming much of your content. Similar to Jeremy and Zach, the inspiration to just get out there and build, write, contribute, and share has actively changed the way I see the world and I’m spending my days differently because of what you’ve written, thankyou.
Paul Kennedy | University of Technology Sydney
Paul without your introduction to Data Mining course which I took in 2017 (if I’m honest I picked it on a whim thinking I’d learn something about marketing which I thought would be important, I’m happy I was so wrong) I wouldn’t have even started writing code professionally and I wouldn’t have dove deep into machine learning and data science like I have. Your first lesson explaining your cancer research using ML is still a vivid memory and constant source of inspiration for me loving what I do and being so fascinated with data science and ML. That single elective completely changed my professional path and graduate program rotations at work, I totally shifted from being a business analyst (extremely useful and practical skills for shipping software in a big org but completely unsatisfying long term) to finding anyone and anywhere doing ‘data’ which led me to the early ‘big data platform’ which has been some of the best years of my life in learning. I hope one day to be able to payback the inspiration or collaborate in some way, thankyou.
Tim Spencer | Westpac
Tim, I probably wouldn’t have found fastai and so many wonderful data science writers and contributors out there without you flagging them to me. Almost all my favourite contributors that I follow are from tweets or blogs you’ve shared. You’ve got an awesomely practical mind and I’ve learnt so much from your working behaviours + passion and interest for doing good work and doing great data work. You’re a cool operator and I hope one day to have the poise and calmness of thought you ooze. So many of the people I’ve mentioned above are because you’ve put me onto them, its difficult to overstate the impact the exposure has had despite the content not being yours. I genuinely aim to be an engineer and data professional like you over the next ~15 years and if you’re ever trying to build something and want help, please always feel comfortable giving me a buzz! Thankyou.
If anyone mentioned in this list ever read this, please know you’ve made a demonstrable and incredibly large positive influence on my life, I owe you a debt and if you’d ever feel comfortable reaching out to me, please do! I’d love to explain in more detail how thankful I am.
I would like to use the Kaggle competition that is currently running called “RSNA Screening Mammography Breast Cancer Detection” through this chapter. Hopefully I can apply what I learn in subsequent chapters to get better within the competition.
The first step is to get our data, I’m pretty sure I can use the kaggle python APIs in order to do this.
!kaggle competitions list
ref deadline category reward teamCount userHasEntered
---------------------------------------------------------------------------------- ------------------- --------------- --------- --------- --------------
https://www.kaggle.com/competitions/nfl-player-contact-detection 2023-03-01 23:59:00 Featured $100,000 218 False
https://www.kaggle.com/competitions/nfl-big-data-bowl-2023 2023-01-09 23:59:00 Analytics $100,000 0 False
https://www.kaggle.com/competitions/godaddy-microbusiness-density-forecasting 2023-03-14 23:59:00 Featured $60,000 438 False
https://www.kaggle.com/competitions/learning-equality-curriculum-recommendations 2023-03-14 23:59:00 Featured $55,000 152 False
https://www.kaggle.com/competitions/santa-2022 2023-01-17 23:59:00 Featured $50,000 575 False
https://www.kaggle.com/competitions/rsna-breast-cancer-detection 2023-02-27 23:59:00 Featured $50,000 599 True
https://www.kaggle.com/competitions/otto-recommender-system 2023-01-31 23:59:00 Featured $30,000 1740 False
https://www.kaggle.com/competitions/novozymes-enzyme-stability-prediction 2023-01-03 23:59:00 Featured $25,000 2409 False
https://www.kaggle.com/competitions/g2net-detecting-continuous-gravitational-waves 2023-01-03 23:59:00 Research $25,000 905 False
https://www.kaggle.com/competitions/titanic 2030-01-01 00:00:00 Getting Started Knowledge 13917 False
https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques 2030-01-01 00:00:00 Getting Started Knowledge 4516 True
https://www.kaggle.com/competitions/spaceship-titanic 2030-01-01 00:00:00 Getting Started Knowledge 2803 False
https://www.kaggle.com/competitions/digit-recognizer 2030-01-01 00:00:00 Getting Started Knowledge 1287 False
https://www.kaggle.com/competitions/nlp-getting-started 2030-01-01 00:00:00 Getting Started Knowledge 912 False
https://www.kaggle.com/competitions/connectx 2030-01-01 00:00:00 Getting Started Knowledge 204 False
https://www.kaggle.com/competitions/tpu-getting-started 2030-06-03 23:59:00 Getting Started Knowledge 154 False
https://www.kaggle.com/competitions/store-sales-time-series-forecasting 2030-06-30 23:59:00 Getting Started Knowledge 909 False
https://www.kaggle.com/competitions/gan-getting-started 2030-07-01 23:59:00 Getting Started Prizes 91 True
https://www.kaggle.com/competitions/contradictory-my-dear-watson 2030-07-01 23:59:00 Getting Started Prizes 70 False
# If I wanted to download the data via the API I would run the below command but its ~300GB and I'd like to continue to explore with this notebook in the mean-time so I# will set this to download in the background and I'll continue with an example dataset that I build along with the book.# !kaggle competitions download rsna-breast-cancer-detection -p ../data/rsna_data
Ok upon realising it will take a day or so to download the competition data, I will work with a smaller dataset in the mean-time! Lets use sharks instead of bears from the book example whilst I wait for my rsna data to download
Path looks good, lets download all our scary sharks.
%%timepath.mkdir(exist_ok=True)# make the path firstfor shark in shark_types: dest = path/shark dest.mkdir(exist_ok=True) results = search_images_ddg(f"{shark} shark") download_images(dest, urls=results)
OK so at this point I can see there are some interesting functions like map being run directly from this failed object rather than the python inbuilt and I’m curious as to what this failed object type actually is and what map does
type(failed), doc(failed.map)
L.map
L.map(f, *args, gen=False, **kwargs)
Create new `L` with `f` applied to all `items`, passing `args` and `kwargs` to `f`
This is cool, this fastcore ‘L’ type acts like a list but I can just call map and apply a given function to all items in it. I suspect this is tickling the surface of how this could be used but thats a helpful api instead of playing with python’s inbuilt map function. Although I’m fairly sure the syntax is very similar. Lets also checkout unlink which we’re about to run over the failed images.
doc(Path.unlink)
Path.unlink
Path.unlink(missing_ok=False)
Remove this file or link.
If the path is a directory, use rmdir() instead.
Ok simply a delete, easy as. So in this case, we have a bunch of items contained within failed.items where we will call unlink on each one
now if I verify the images again, I should turn up with an empty ‘L’
failed = verify_images(path)failed
'WindowsPath' object is not iterable
(#0) []
From Data to DataLoaders
Ok now that we’ve gathered a bunch of data, we can now move it into one of the key concepts and classes of fastai which is the DataLoader object, lets have a quick look at the docs
Ok so this is a pytorch concept directly which has been wrapped with extra functionality, lets have a quick look at the pytorch docs
torch.utils.data.dataloader.DataLoader?
Init signature:
torch.utils.data.dataloader.DataLoader( dataset: torch.utils.data.dataset.Dataset[+T_co], batch_size: Optional[int]=1, shuffle: Optional[bool]=None, sampler: Union[torch.utils.data.sampler.Sampler, Iterable, NoneType]=None, batch_sampler: Union[torch.utils.data.sampler.Sampler[Sequence], Iterable[Sequence], NoneType]=None, num_workers: int =0, collate_fn: Optional[Callable[[List[~T]], Any]]=None, pin_memory: bool =False, drop_last: bool =False, timeout: float =0, worker_init_fn: Optional[Callable[[int], NoneType]]=None, multiprocessing_context=None, generator=None,*, prefetch_factor: int =2, persistent_workers: bool =False, pin_memory_device: str ='',)Docstring:
Data loader. Combines a dataset and a sampler, and provides an iterable over
the given dataset.
The :class:`~torch.utils.data.DataLoader` supports both map-style and
iterable-style datasets with single- or multi-process loading, customizing
loading order and optional automatic batching (collation) and memory pinning.
See :py:mod:`torch.utils.data` documentation page for more details.
Args:
dataset (Dataset): dataset from which to load the data.
batch_size (int, optional): how many samples per batch to load
(default: ``1``).
shuffle (bool, optional): set to ``True`` to have the data reshuffled
at every epoch (default: ``False``).
sampler (Sampler or Iterable, optional): defines the strategy to draw
samples from the dataset. Can be any ``Iterable`` with ``__len__``
implemented. If specified, :attr:`shuffle` must not be specified.
batch_sampler (Sampler or Iterable, optional): like :attr:`sampler`, but
returns a batch of indices at a time. Mutually exclusive with
:attr:`batch_size`, :attr:`shuffle`, :attr:`sampler`,
and :attr:`drop_last`.
num_workers (int, optional): how many subprocesses to use for data
loading. ``0`` means that the data will be loaded in the main process.
(default: ``0``)
collate_fn (Callable, optional): merges a list of samples to form a
mini-batch of Tensor(s). Used when using batched loading from a
map-style dataset.
pin_memory (bool, optional): If ``True``, the data loader will copy Tensors
into device/CUDA pinned memory before returning them. If your data elements
are a custom type, or your :attr:`collate_fn` returns a batch that is a custom type,
see the example below.
drop_last (bool, optional): set to ``True`` to drop the last incomplete batch,
if the dataset size is not divisible by the batch size. If ``False`` and
the size of dataset is not divisible by the batch size, then the last batch
will be smaller. (default: ``False``)
timeout (numeric, optional): if positive, the timeout value for collecting a batch
from workers. Should always be non-negative. (default: ``0``)
worker_init_fn (Callable, optional): If not ``None``, this will be called on each
worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as
input, after seeding and before data loading. (default: ``None``)
generator (torch.Generator, optional): If not ``None``, this RNG will be used
by RandomSampler to generate random indexes and multiprocessing to generate
`base_seed` for workers. (default: ``None``)
prefetch_factor (int, optional, keyword-only arg): Number of batches loaded
in advance by each worker. ``2`` means there will be a total of
2 * num_workers batches prefetched across all workers. (default: ``2``)
persistent_workers (bool, optional): If ``True``, the data loader will not shutdown
the worker processes after a dataset has been consumed once. This allows to
maintain the workers `Dataset` instances alive. (default: ``False``)
pin_memory_device (str, optional): the data loader will copy Tensors
into device pinned memory before returning them if pin_memory is set to true.
.. warning:: If the ``spawn`` start method is used, :attr:`worker_init_fn`
cannot be an unpicklable object, e.g., a lambda function. See
:ref:`multiprocessing-best-practices` on more details related
to multiprocessing in PyTorch.
.. warning:: ``len(dataloader)`` heuristic is based on the length of the sampler used.
When :attr:`dataset` is an :class:`~torch.utils.data.IterableDataset`,
it instead returns an estimate based on ``len(dataset) / batch_size``, with proper
rounding depending on :attr:`drop_last`, regardless of multi-process loading
configurations. This represents the best guess PyTorch can make because PyTorch
trusts user :attr:`dataset` code in correctly handling multi-process
loading to avoid duplicate data.
However, if sharding results in multiple workers having incomplete last batches,
this estimate can still be inaccurate, because (1) an otherwise complete batch can
be broken into multiple ones and (2) more than one batch worth of samples can be
dropped when :attr:`drop_last` is set. Unfortunately, PyTorch can not detect such
cases in general.
See `Dataset Types`_ for more details on these two types of datasets and how
:class:`~torch.utils.data.IterableDataset` interacts with
`Multi-process data loading`_.
.. warning:: See :ref:`reproducibility`, and :ref:`dataloader-workers-random-seed`, and
:ref:`data-loading-randomness` notes for random seed related questions.
File: c:\users\nick\anaconda3\envs\fastai\lib\site-packages\torch\utils\data\dataloader.py
Type: type
Subclasses:
The important statements on my first read seem to be understanding that a dataloader gives you a way to iterate/sample the dataset in multiple ways, whether that be a sample or a batch or a single record.
Then the concept of a DataBlock is introduced which is paraphrased as “a way to fully customise every stage of the creation of your DataLoaders.”
Lets now look at the docs and make a Dataloaders for the shark dataset we downloaded
Signature: ImageBlock(cls:'PILBase'=<class'fastai.vision.core.PILImage'>)Source:def ImageBlock(cls:PILBase=PILImage):"A `TransformBlock` for images of `cls`"return TransformBlock(type_tfms=cls.create, batch_tfms=IntToFloatTensor)File: c:\users\nick\anaconda3\envs\fastai\lib\site-packages\fastai\vision\data.py
Type: function
It returns a TransformBlock which we also haven’t seen yet
Ok looks like this is a more generic type to connect transformations of some type that I’m not sure of yet to the DataBlocks. Not quite sure yet what these mean but march on we must.
Signature:
CategoryBlock( vocab:'list | pd.Series'=None, sort:'bool'=True, add_na:'bool'=False,)Docstring: `TransformBlock` for single-label categorical targets
File: c:\users\nick\anaconda3\envs\fastai\lib\site-packages\fastai\data\block.py
Type: function
Looks like CategoryBlock also returns a TransformBlock so once we figure that out, it’ll be the same logic but important for Category instead of Image
The book describes the ‘blocks’ keywords as a tuple of the independent and dependent variables, so we’re inputting an ImageBlock and outputting a CategoryBlock, the importance of the TransformBlock class isn’t obvious at the moment but I’m hypothesising its a standard way to link A–>B. For example in this case we want to link each ImageBlock–>CategoryBlock.
The item_tfms keyword is to manage transformations we need to apply on our input (images in this case) and we need to make sure all our images are the same size to feed my tiny baby GPU in batches. This blog & 2023’s work will hopefully fry my GeForce GTX 960 so that I can have an excuse for a new PC build, but for now my 2GB of 2015 memory will have to do.
Ok we should now be ready to create our DataLoaders object, using the path object we created our dataset with.
At this point the book described the problems with each of these approaches, in particular how we either lose signal with a crop, waste compute and lose resolution with the pad, or create unrealistic images with the squish and stretch. I won’t repeat them here but just re-iterating the significance of these steps, below we will run the RandomResizedCrop method which will randomly resize and crop each epoch which creates the effect of looking at the same image with slightly different framing each time.
# Make a learnerlearn = vision_learner(dls, resnet34, metrics=error_rate)learn.fine_tune(4)
C:\Users\Nick\Anaconda3\envs\fastai\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
C:\Users\Nick\Anaconda3\envs\fastai\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet34_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet34_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
epoch
train_loss
valid_loss
error_rate
time
0
2.417486
1.404847
0.409574
01:29
C:\Users\Nick\Anaconda3\envs\fastai\lib\site-packages\PIL\Image.py:979: UserWarning: Palette images with Transparency expressed in bytes should be converted to RGBA images
warnings.warn(
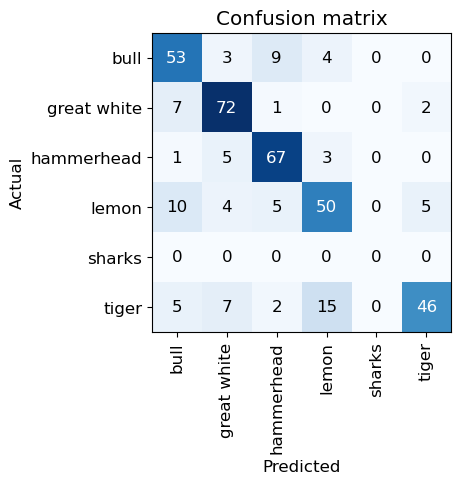
OK a decent chunk of mistakes but surprisingly good for how tiny the model is and how small the photographs are. The biggest error being Tiger sharks being mistaken for great white sharks but great white sharks not being mistaken for Tigers which is interesting. I’m sure a lot of this leads to strange photographs with edits in them such as words and other problems like lighting and in general underwater photography being more complicated. Also who’s getting close enough to sharks to take these kind of photos, not me certainly.
Really interesting is that second photo of a bull shark being mistaken for a hammerhead, I think the angle of the photograph with the side fins are being mistaken for the distinctive hammerhead eyes.
Lets now use the cleaner object to improve the dataset
cleaner = ImageClassifierCleaner(learn)cleaner
No wonder a bunch of bull sharks were misinterpeted as great white’s, they bloody well are! I’m not a shark expert but the distinctive white underbelly and distinctive rippling in between the grey and white with the pointy nose are features of great white sharks and a few bull sharks here I think are actually great white sharks so I’ve changed the labelling to suit. Great white sharks are also known as white pointers, I suspect due to this very pointy nose shape they have
# Lets make those changes that I did in the above sectionfor idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]),path/cat)
Turning our Model into an Online Application
Now is the section where we go deploying this model we’ve made, I’m actually keen on using some Azure services as I’ve had to interact with that ecosystem at work and I’d like to get a little bit more in the weeds. If I end up spending way too much time deploying said model then I’ll retreat back to the guides provided within fastai but I’m willing to step a little bit outside of my comfort zone here.
Using the Model for Inference
Lets quickly play around with exporting the model pickle and loading it back up as well to make a prediction
As mentioned in the book, we have the predicted category, the index of the predicted category in the vocab of our learner and the probabilities of each category, we can checkout the model vocab on the object and see the 2nd value (1st index) being ‘great white’
This is the section where the book describes voila, I think in the lecture, Gradio is used, I’ve also come across Vercel as infrastructure to deploy to from the fastai study group contributer @ielka. I myself have thought about using Azure, I’ll revisit this in the future as I’d like to get deeper in the course before getting stuck down in the details of deployment but I will keep this in the back of my mind.
Deployed on Gradio and HuggingFace Spaces
I’m going to follow Jeremy’s example and simply use Gradio and HuggingFace for now, below is the exported script I’m going to use with nbdev to deploy to hugging face.